


Bu çalışma, üniversite bölüm tercih sıralamaları için geleneksel "geçen yıl kaçla kapatmış?" yaklaşımının yerine, fark tabanlı trend analizi ve kontenjan düzeltmeli tahmin modelini önermektedir. Önerilen yöntem, yıllar arası fark serileri analizi, kontenjan etkisi modellemesi ve varyans düzeltmeli güven aralığı oluşturma tekniklerini birleştirerek daha bilimsel ve güvenilir tahminler sunmaktadır.
Üniversite tercihi yapma süreci, öğrenciler ve aileler için kritik bir karar verme aşamasıdır. Geleneksel olarak rehberlik ve psikolojik danışmanlık hizmetleri, "geçen yıl bu bölüm kaçıncı sırayla kapatmış?" sorusuna dayalı basit bir yaklaşım benimser. Ancak bu yaklaşım, birçok önemli faktörü göz ardı etmekte ve yanıltıcı sonuçlara yol açabilmektedir. Bu çalışmada, öğrenci davranışlarının dinamik yapısını ve kontenjan değişimlerinin etkisini dikkate alan yeni bir metodoloji önerilmektedir:
Fark Tabanlı Trend Tahmini ve Varyans Düzeltmeli Aralık Kestirimi
2. Metodoloji
2.1 Yıllar Arası Fark Alma (Fark Serileri Analizi)
Geleneksel yaklaşımlar ham sıralama değerlerini kullanırken, önerilen yöntem değişim hızlarına odaklanır. Bu yaklaşımın temel avantajları:
- Trend Görünürlüğü: Ham sıralama değerleri yerine değişim oranları kullanılarak eğilimler doğrudan gözlemlenebilir
- Stabilite: Öğrenci kitlesel davranışının göreli olarak yavaş değişmesi nedeniyle farklar daha stabil özellik gösterir
- Öngörülebilirlik: Özellikle 1.5 milyon sıralamasının üstündeki (daha popüler) bölümlerde kitlenin davranışı daha öngörülebilir hale gelir.
2.2 Kontenjan Etkisinin Düzeltilmesi
Bölüm kontenjanlarındaki değişimler sıralama üzerinde doğrudan etki oluşturur. Kontenjan azaldığında sıralamanın öne çekilmesi, tahmin doğruluğunu olumsuz etkileyebilir. Bu nedenle:
- Kontenjan artışı durumunda: Tahmin değerine pozitif düzeltme
- Kontenjan azalışı durumında: Tahmin değerinden negatif düzeltme
Bu düzeltme mekanizması, tam bir kontenjan etkisi modellemesi sağlayarak tahmin kalitesini artırır.
2.3 Varyans Düzeltmeli Güven Aralığı
Nokta tahmin yerine aralık tahmini kullanılması, belirsizliği quantifiye ederek daha gerçekçi beklentiler oluşturur. Yöntem:
- En düşük ve en yüksek fark değerleri belirlenir
- Standart sapma hesaplanır
- Güven aralığı oluşturulur: [alt_limit ± standart_sapma, üst_limit ± standart_sapma]
- Uygulama Örneği
3.1 Veri Seti
Adnan Menderes Üniversitesi Toprak Bilimi ve Bitki Besleme Bölümü verileri:
- 2022 yılı sıralama: 497.259
- 2023 yılı sıralama: 525.172
- 2024 yılı sıralama: 545.008
3.2 Fark Hesaplama
2023-2022 farkı: 525.172 - 497.259 = 27.913
2024-2023 farkı: 545.008 - 525.172 = 19.836
3.3 Kontenjan Düzeltmeli Tahmin
Kontenjan azalışı varsayımı altında:
- Alt tahmin: 545.008 - 27.913 = 517.095
- Üst tahmin: 545.008 - 19.836 = 525.172
Ham tahmin aralığı: 517.095 - 525.172
3.4 Standart Sapma Hesaplama
Ortalama (μ) = (27.913 + 19.836) / 2 = 23.8745
Varyans hesaplama:
- (27.913 - 23.8745)² = 16.3095
- (19.836 - 23.8745)² = 16.3095
Popülasyon varyansı = (16.3095 + 16.3095) / 2 = 16.3095
Standart sapma = √16.3095 = 4.039
3.5 Final Tahmin
Güven aralığı: 517.095 - 525.172
Hata payı: ±4.039
Bu, öğrencinin yaklaşık 517.000-525.000 sıralama aralığında tercih yapması gerektiğini ve ±4.000 sapma beklentisi olduğunu gösterir. - Algoritma Implementasyonu
Önerilen metodoloji Python programlama dili kullanılarak otomatize edilmiştir. Algoritma, veri girişi alarak otomatik olarak fark hesaplama, kontenjan düzeltme ve güven aralığı oluşturma işlemlerini gerçekleştirir.
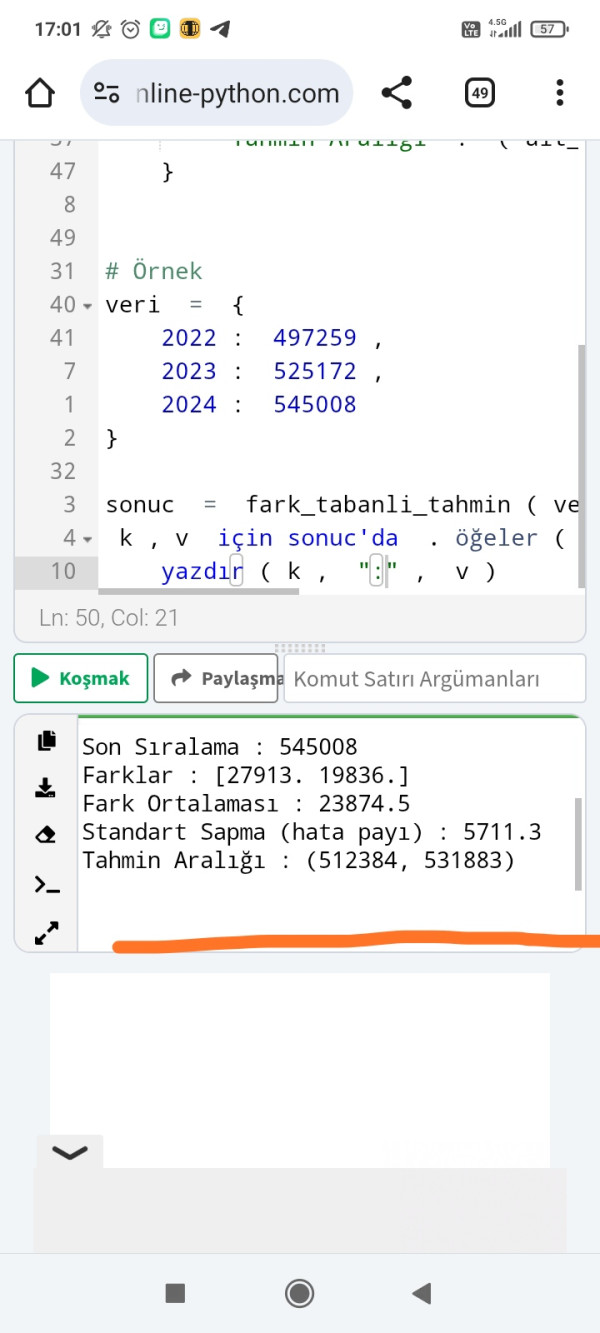
python
import pandas as pd
import numpy as np
def fark_tabanli_tahmin(veri, kontenjan_degisim=0):
"""
Fark tabanlı trend + kontenjan düzeltmeli tahmin aralığı
veri: dict {yıl: sıralama}
kontenjan_degisim: (+) artış, (-) azalış
"""
Veriyi sırala
df = pd.DataFrame(list(veri.items()), columns=["Yıl", "Sıralama"])
df = df.sort_values("Yıl").reset_index(drop=True)
Yıllar arası farklar
df["Fark"] = df["Sıralama"].diff()
son_siralama = df["Sıralama"].iloc[-1]
farklar = df["Fark"].dropna().values
min_fark, max_fark = farklar.min(), farklar.max()
ort, std = np.mean(farklar), np.std(farklar, ddof=1) # örnek std
Tahmin aralığı (kontenjan düzeltmesi + std dahil)
alt_tahmin = son_siralama - max_fark - kontenjan_degisim - std
ust_tahmin = son_siralama - min_fark - kontenjan_degisim + std
Negatif kontrol
alt_tahmin, ust_tahmin = max(1, round(alt_tahmin)), max(1, round(ust_tahmin))
return {
"Veri Tablosu": df,
"Son Sıralama": son_siralama,
"Farklar": farklar,
"Fark Ortalaması": round(ort, 2),
"Standart Sapma (hata payı)": round(std, 2),
"Tahmin Aralığı": (alt_tahmin, ust_tahmin)
}
Örnek
veri = {
2022: 497259,
2023: 525172,
2024: 545008
}
sonuc = fark_tabanli_tahmin(veri, kontenjan_degisim=-1000)
for k,v in sonuc.items():
print(k, ":", v)
- Geleneksel Yöntemlerle Karşılaştırma
5.1 Sosyal Bilimler Danışmanlığının Zayıflıkları
Mevcut rehberlik hizmetlerinin temel sorunları:
- Tek boyutlu yaklaşım: Sadece bir önceki yılın kapanış sıralamasına odaklanma
- Kontenjan etkisini göz ardı etme: Bölüm kontenjan değişimlerinin sıralama üzerindeki etkisini hesaplamama
- Belirsizlik quantifikasyonunun olmaması: Nokta tahmin kullanarak risk değerlendirmesi yapmama
- Trend analizinin eksikliği: Çok yıllık eğilimleri dikkate almama
5.2 Önerilen Yöntemin Üstünlükleri
- Bilimsel temelli: İstatistiksel yöntemler ve trend analizi kullanır
- Çok faktörlü: Kontenjan değişimi, historik trend ve varyans etkilerini birleştirir
- Risk farkındalığı: Güven aralığı ile belirsizliği quantifiye eder
- Otomatize edilebilir: Programlama ile ölçeklenebilir hale getirilebilir
Fark tabanlı trend tahmini ve varyans düzeltmeli aralık kestirimi, üniversite tercih danışmanlığında paradigma değişimi sağlayacak potansiyele sahiptir. Bu yöntem: - Daha yüksek doğruluk sağlar, özellikle popüler bölümlerde
- Risk yönetimi imkanı sunar güven aralıkları ile
- Bilimsel güvenilirlik getirir istatistiksel temeller sayesinde
- Ölçeklenebilirlik sağlar otomatizasyon potansiyeli ile
Gelecek Çalışmalar
- Farklı alan ve üniversite türleri için model validasyonu
- Makine öğrenmesi tekniklerinin entegrasyonu
- Gerçek zamanlı veri işleme sistemlerinin geliştirilmesi
- Öğrenci profili bazında kişiselleştirme algoritmaları
Bu metodoloji, eğitim danışmanlığının bilimsel zemine oturtulması ve öğrenci memnuniyetinin artırılması açısından önemli bir adım teşkil etmektedir.


